
- 2023-07-30
- Technological Stack for Cloud Digital Twin
- Technological Stack for Local Digital Twin
- Resume of Technological Stack
- Streamlit
- InfluxDB + Streamlit
- Grafana + InfluxDB + Node-RED
- Streamlit + Kafka
- Review of Digital Twin + Predictive
- Framework
- Project Examples
- Quix: no TimeDB, Kafka under the Hood
- Hono - Ditto
- Kafka vs MQTT
- IMPORTANT INTERESTING PROJECT
- Data Connectivity
- Cloud Platform
2023-07-30
- 2023-07-30
- Technological Stack for Cloud Digital Twin
- Technological Stack for Local Digital Twin
- Resume of Technological Stack
- Streamlit
- InfluxDB + Streamlit
- Grafana + InfluxDB + Node-RED
- Streamlit + Kafka
- Review of Digital Twin + Predictive
- Framework
- Project Examples
- Quix: no TimeDB, Kafka under the Hood
- Hono - Ditto
- Kafka vs MQTT
- IMPORTANT INTERESTING PROJECT
- Data Connectivity
- Cloud Platform
2023-07-30
Technological Stack for Cloud Digital Twin
- Cloud Platform: To deploy the machine learning model in the cloud and handle data processing, you can choose from popular cloud platforms like Amazon Web Services (AWS), Microsoft Azure, Google Cloud Platform (GCP), or IBM Cloud. These platforms provide the necessary infrastructure and services for hosting applications and managing resources.
- Machine Learning Framework: Select a machine learning framework that supports training and retraining of models in the cloud. Popular choices include TensorFlow, PyTorch, and scikit-learn. These frameworks provide tools and libraries for building, training, and deploying machine learning models.
- Time Series Database: Use a time series database to store and manage the streamed time series data. InfluxDB or TimescaleDB are commonly used databases for handling time series data efficiently.
- Web Application Framework: For creating the web application to display the data and inference results, you can use web application frameworks such as Django, Flask (Python-based), or Node.js (JavaScript-based). These frameworks enable you to develop web applications and provide REST APIs for communication between the web app and backend services.
- Real-time Data Streaming: For handling the real-time streaming of time series data from sensors to the cloud, consider using technologies like Apache Kafka or Amazon Kinesis. These platforms can handle data ingestion and processing at scale.
- Web Sockets: To facilitate real-time updates in the web application, use WebSockets. WebSocket technology enables bidirectional communication between the server and web browsers, allowing for real-time updates of the displayed data.
- Visualization Library: Utilize a data visualization library like D3.js or Plotly to create interactive and informative charts and graphs to display the time series data and inference results.
- Authentication and Authorization: Implement user authentication and authorization mechanisms in the web application to ensure secure access to the displayed data.
- Containerization: Consider containerizing your application using Docker to package all the components and dependencies, making it easier to deploy and manage across different environments.
- Continuous Integration and Continuous Deployment (CI/CD): Implement CI/CD pipelines to automate the testing, building, and deployment of the application, ensuring smooth updates and maintenance.
Technological Stack for Local Digital Twin
- Machine Learning Framework: Select a machine learning framework that supports training and retraining of models on the PC. Popular choices include TensorFlow, PyTorch, scikit-learn, or XGBoost. These frameworks provide tools and libraries for building, training, and deploying machine learning models locally.
- Time Series Database: Use a time series database to store and manage the streamed time series data on the PC. InfluxDB or TimescaleDB are commonly used databases for handling time series data efficiently.
- Data Preprocessing: Implement data preprocessing pipelines to process and clean the time series data collected from the sensors. Tools like Pandas and NumPy in Python can be helpful for data manipulation and preparation.
- Real-time Data Streaming: For handling the real-time streaming of time series data from sensors to the PC, consider using technologies like Apache Kafka or RabbitMQ. These platforms can handle data ingestion and processing in real-time.
- Web Application Framework: For creating the web application to display the data and inference results, you can use web application frameworks such as Django, Flask (Python-based), or Node.js (JavaScript-based). These frameworks enable you to develop web applications and provide REST APIs for communication between the web app and backend services.
- Web Sockets: To facilitate real-time updates in the web application, use WebSockets. WebSocket technology enables bidirectional communication between the server and web browsers, allowing for real-time updates of the displayed data.
- Data Visualization Library: Utilize a data visualization library like D3.js or Plotly to create interactive and informative charts and graphs to display the time series data and inference results. Grafana.
- Local Hosting: The web application and other services can be locally hosted on the PC. You can use tools like NGINX or Apache to serve the web application.
- Authentication and Authorization: Implement user authentication and authorization mechanisms in the web application to ensure secure access to the displayed data.
- Containerization (Optional): Consider containerizing your application using Docker to package all the components and dependencies, making it easier to deploy and manage.
- Streaming Data Processing (Optional): For more complex data processing tasks, consider using stream processing frameworks like Apache Flink or Apache Spark Streaming.
Resume of Technological Stack
- Machine Learning Framework: TensorFlow, PyTorch, scikit-learn, or XGBoost.
- Time Series Database: InfluxDB or TimescaleDB.
- Data Preprocessing: Pandas and NumPy, Node-RED.
- Real-time Data Streaming: Apache Kafka or RabbitMQ. .
- Web Application Framework: Django, Flask (Python-based), or Node.js (JavaScript-based), Streamlit
- Web Sockets: WebSockets.
- Data Visualization Library: D3.js or Plotly. Grafana.
- Local Hosting: NGINX or Apache.
- Authentication and Authorization
- Containerization (Optional): Docker.
- Streaming Data Processing (Optional): Apache Flink or Apache Spark Streaming.
- Continuous Integration and Continuous Deployment (CI/CD):
Streamlit
- Streamlit is an open-source Python library that makes it easy to create interactive web applications for machine learning and data science projects. With Streamlit, you can quickly build and deploy web apps using simple Python scripts, without needing to have any web development experience. Streamlit provides a user-friendly interface for creating interactive visualizations, displaying data, and allowing users to interact with your models or analysis. It also supports real-time updates, so you can easily iterate and make changes to your app as you develop it. Overall, Streamlit is a powerful tool for creating and sharing data-driven web applications.
- Alternative to Django or Flask
- Examples
Streamlit + streaming
- ash2shukla/streamlit-stream: A template for creating streamlit apps that consume streaming data
- How to handle streaming data in Streamlit
- How to build a real-time live dashboard with Streamlit
- (41) Real-time analytics dashboard with Streamlit, Pinot & Kafka | Mark Needham | Conf42 Python 2022 - YouTube
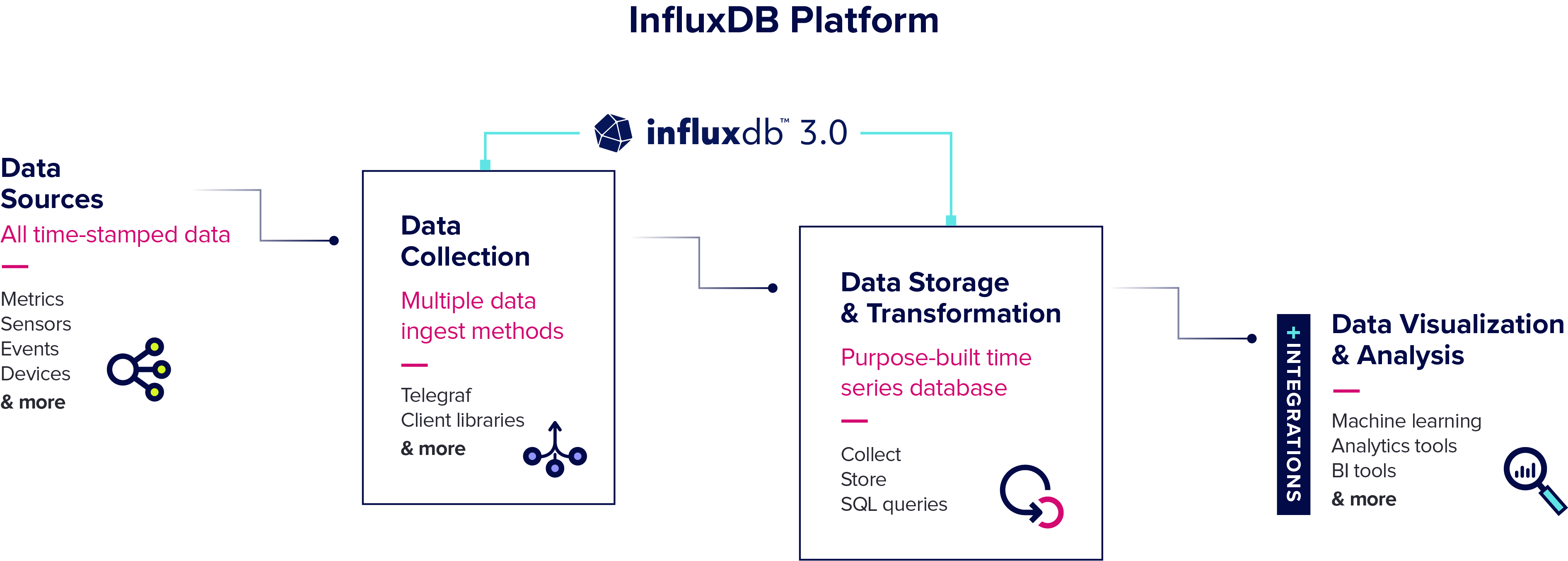
InfluxDB + Streamlit
- InfluxDB is a high-performance, open-source time series database. It is designed to handle large amounts of time-stamped data and enables fast storage and retrieval of time series data for real-time analytics and monitoring purposes. InfluxDB uses a flexible data model that allows storing, querying, and aggregating data based on time intervals, making it well-suited for applications that require tracking and analyzing time series data, such as IoT sensor data, monitoring systems, and financial data.
- Telegraf is a server-based agent for collecting and sending all metrics and events from databases, systems, and IoT sensors. Telegraf is written in Go and compiles into a single binary with no external dependencies, and requires a very minimal memory footprint.
- Telegraf | InfluxData
- Sample data | InfluxDB OSS 2.7 Documentation
- Visualize Data with Streamlit and InfluxDB | InfluxData
Grafana + InfluxDB + Node-RED
(41) Build Low-code Operational Digital Twins with Node-RED, InfluxDB and Grafana - YouTube
Streamlit + Kafka
- Conf42: Building a real-time analytics dashboard with Streamlit, Apache Pinot, and Apache Kafka Streamlit+Kafka+Pinot
- Featured Series: Building Streaming Data Pipelines • Supertype Streamlit+Kafka+Spark
- FOSDEM 2023 - Building A Real-Time Analytics Dashboard with Streamlit, Apache Pinot, and Apache Pulsar Stramlit+Pinot+Pulsar
Review of Digital Twin + Predictive
(41) "Predictive Digital Twins: From physics-based modeling to scientific machine learning" Prof. Willcox - YouTube Karen Willcox
Framework




Project Examples
Herrera (almeaibedDigitalTwinAnalysis2021, link, DOI, zolib) uses Model Predictive Controller for Green House control. Code is available. (steindlSemanticMicroserviceFramework2021, link, DOI, zolib)
Quix: no TimeDB, Kafka under the Hood
- Home | Quix
- (41) Quix - YouTube
- quixio/quix-streams: Quix Streams - A library for telemetry data streaming. Python Stream Processing
Hono - Ditto
Eclipse Hono provides remote service interfaces for connecting large numbers of IoT devices and interacting with them in a uniform way regardless of the device communication protocol. Hono supports devices communicating via common IoT protocols, as standard, such as HTTP, MQTT and AMQP. Eclipse Ditto is a framework that supports IoT Digital twins software pattern implementation. Ditto’s capabilities includes: mirrors physical assets/devices, acts as a “single source of truth” for a physical asset, provides aspects and services around devices, and keeps real and digital worlds in sync. Apache Kafka enables the building of data pipelines for real-time streaming applications. Kafka is seamlessly horizontally scalabe, false tolerant and high speed. The three main capabilities of Kafka is to, 1. publish and subscribe to stream of records, 2. store these records in fault tolerant way, and 3. process them as they occur. Influx DB is a real-time series database, which is simple to setup and scale. Grafana is an analytics and monitoring solution which provides plugin data source models and support for many of the most popular time series database
There are many technologies that can be used to realize bidirectional communication. For example, Ditto and RabbitMQ as mentioned above.
Many different technologies already exist for tackling the communication issues, i.e. RabbitMQ (https://www.rabbitmq.com/), Ditto(https://www.eclipse.org/ditto/), Apache Kafka(https://kafka.apache.org/), and https://www.rti.com/. In our case, we chose RabbitMQ to serve as a data broker because of its lightweight and easy deployment on premise.
Regarding data storage, we used InfluxDB for its ease of use, its bindings to different programming languages, and its simple visualization facilities.
Recent advances in tools for creating visual interfaces such as Unity(https://unity.com/), Qt(https://www.qt.io/). Grafana, Dash, Gazebo, and so on, have made it easier to create intuitive and visual interfaces for a DS. One of the challenges in DT engineering is the rapid construction of these interfaces from a PT. Such interfaces should, for example, allow the user to: 1) Selectively visualize the 3D PT and its state; 2) Create dashboards to plot the most important data; 3) Replay past behavior of the PT; 4) Spawn new what-if simulations; 5) Run optimizations; 6) Display predictive maintenance results;
Kafka vs MQTT
- MQTT vs Kafka: An IoT Advocate's Perspective (Part 1 - The Basics) | InfluxData
- MQTT vs Kafka: An IoT Advocate’s Perspective (Part 2 – Kafka the Mighty) | InfluxData
- MQTT vs Kafka: An IoT Advocate’s Perspective (Part 3 - A Match Made in Heaven) | InfluxData
- Apache Kafka and MQTT (Part 1 of 5) - Overview and Comparison - Kai Waehner
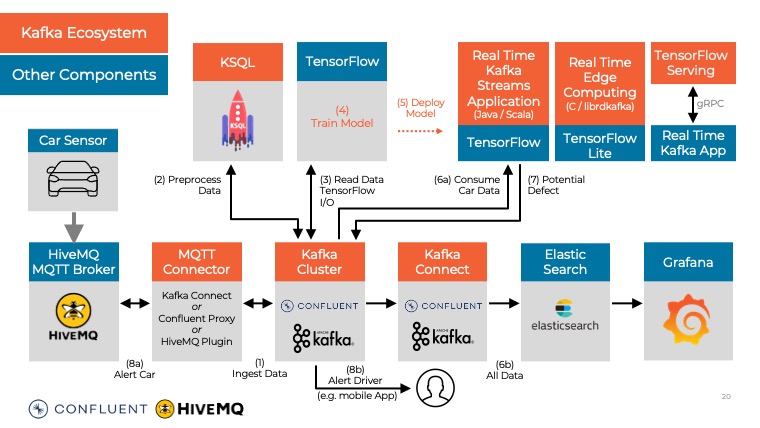
IMPORTANT INTERESTING PROJECT
kaiwaehner/hivemq-mqtt-tensorflow-kafka-realtime-iot-machine-learning-training-inference: Real Time Big Data / IoT Machine Learning (Model Training and Inference) with HiveMQ (MQTT), TensorFlow IO and Apache Kafka - no additional data store like S3, HDFS or Spark required Streaming Machine Learning with Tiered Storage hivemq-mqtt-tensorflow-kafka-realtime-iot-machine-learning-training-inference/python-scripts/README.md at master · kaiwaehner/hivemq-mqtt-tensorflow-kafka-realtime-iot-machine-learning-training-inference (41) How to Build a Digital Twin for Thousands of IoT Devices with Apache Kafka and MongoDB - YouTube
TRY THIS BELOW Hello from OpenTwins | OpenTwins (roblesOpenTwinsOpensourceFramework2023, link, DOI, zolib) ertis-research/OpenTwins

Data Connectivity
| HTTP/HTTPS | WebSocket | DDS | MQTT | AMQP |
| --- | --- | --- | --- | --- |
| Transmit data over Internet from applications, websites, and so on | Transmit data over Internet from applications, websites, and so on | Communication bus to connect intelligent machines | Lightweight protocol for collecting data and publishing it to servers and subscribers | Queue system to reliably transfer messages between |
Cloud Platform
| AWS IoT | IBM Watson IoT for Bluemix | PTC ThingWorx | Microsoft Azure IoT |
| --- | --- | --- | --- |
| Free Evaluation | 1-year free trial | 30-day trial, then free Lite version | 30-day trial |